这里算是“丧心病狂”的恶意更新时间,正如之前发表的那篇书评说的那样,苍焰黑银与众不同的武器有两个,一个是烂到不行的画功,还有一个就是浅尝辄止的计算机科学技术了。
从“创新”的角度来看,小人我也希望依靠计算机科学的思维方式和方法——指导自己微不足道的创作实践;进一步地小人我更想用坚实可靠的数学模型真正指导轻小说的创作,现在也只是有了关于模型的那么一点点不可靠的构思。
当然,也多半是妄想,而本次更新的主题是——小人我终于利用SF网上的文本资源,对现在《叛逆的班长大人》这部作品,做了非常基本的统计分析!
如果姑且知道一些“自然语言处理”或者“信息检索”的知识的话,大概就知道TF-IDF完全就是基本中的基本了。
这里也为不知道怎么回事,却无意间看到这里的读者大人,送上一幅小人我画的示意图。
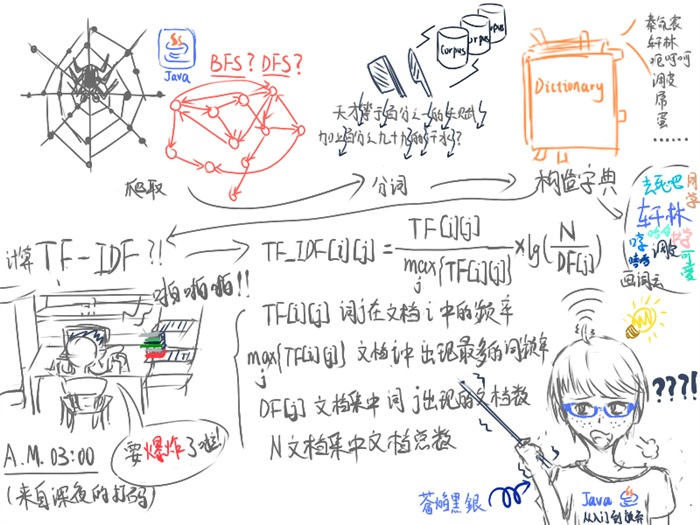
首先是需要获取一定规模的小说文本(爬取),这次小人我用姑且用java写了一个简单的网络爬虫程序,获取到了SF网上某一个时间段小说列表的前500页也的将近1万部作品的原文(后来因为直接这个规模的数据导致内存溢出,果断值用了前50页1千多部作品的原文)。
因为中文说到底属于“黏着语言”,而程序处理的基本单位是词,所以对所有的文本还需要做“自然语言处理”里最基本的分词操作——就是把一句话的意思拆分成一个个合理的词。这个部分是由工具可用的,小人我也就“偷工减料”地用了哈工大的LTP自然语言处理工具,即使开了10个线程,对于那种规模的语料库也花了将近几分钟的时间呢。
接着,对于词为基本单位的处理,还需要统计这么多文档里面到底出现了多少个词,将这些词全部列出来,也就是构造字典的操作了。
所有准备工作都做完后,最重要的就是TF-IDF的计算了,所谓的TF-IDF就是词频-逆文档频率,这个机制根据每个词在不同文档中出现的次数,赋予每个词相对于每个文档的权重——这个权重可以反映对应的词在对应文档中的重要程度!具体的计算方法如上图所示。
最后,依照IF-IDF机制设置的权重,就可以找到对于《叛逆的班长大人》这部作品,最重要的几个词是什么了!对于小人来说,怎么看,就是一件兴奋到不得了的事情!
当然为了更好地表示词的重要性,这里还是使用了“数据可视化”的方法绘制词云,也就是在一幅图中画出对于小人我的作品重要的前20个词是什么——越重要,字就越大——其他的位置、颜色大概是随机设置。
小人我把文档单位设置成一部作品里的一卷,对于《叛逆的班长大人》这部作品来说,就只有可怜的《杂物箱》和《第一卷》了——下面的结果是对于《杂物箱》相对于其他1000多部作品不同卷的最重要的前20个词。

呃,这样看,好像词某有分好呢,“默哀三分钟”硬生生地分出了“默哀三”——不够其他词还是比较明确地反映了主题,没错哦——小人我在《杂物箱》里无病呻吟的事情都是关于小人我烂到不行的插画的事情,像是“封面”(这个权重最大呢)、“画”、“画功”、色稿”都是关于画的事情——而“立志”、“嘚瑟”、“抓头”好像反映了叫人我对自己画功的评价,还算是不错的那结果呢。
那么下面是《第一卷》的IF-IDF结果绘制的词云!

不过这里似乎就稍微逊色一点了,每部小说作品相对于其他作品不同的地方,大概就是一些人民、地名之类的,可能不同的地方还有用于习惯方面,上面的结果算是比较好地反映出来了——但是,对于作品的主题理解,似乎没有什么帮助呢,呃呵呵呵——
嘛,就是一次微不足道的利用计算机科学技术的实践罢了,下面根于这方面的“创新”,我还想使用更加准确的主题模型,针对网络轻小说和商业轻小说小人我也想从统计分析的角度看看到底有什么不同——当然,小人我也想验证自己提出的关于小说剧情的“双波峰”模型,和关于小说人物关系拓扑结构方面的建模——这些问题就留到以后,通过这种方式呈现给大家吧?
另外,关于小说的正文部分,也恳请广大读者朋友提出宝贵意见(我觉得多半看到字数太多就放弃了,或者觉得太啰嗦也放弃了)——还有关注了书评的朋友们,希望不要理解成“我不自量力地把作品没有人气的原因全部推给了‘网络轻小说体制’”——我只是想说“在‘网络轻小说体制’下只有‘丧心病狂’才有机会被知道作品的存在”,这样的残酷现实,至于作品到底好不好,当然只有建立在有人给出宝贵意见的基础上了;然而,小人还是会用“商业轻小说”的标准要求自己的!
下次更新的时候,也想好好重制前面的部分,再实实在在地画一下人物设定。如果有人期待,就甚感欣慰了!
总之,谢谢大家抽出宝贵的时间——阅读到这里,文字方面让您失望了,也是万分抱歉……
叛逆的班长大人提示您:看后求收藏(卧龙小说网http://www.wolongxs.com),接着再看更方便。
好书推荐:《扶她狂想》、《抖S女仆和M的我》、《我的假女友正全力防御她们的进攻》、《我不想和你一起重生》、《女上男下》、《美少女控制我开始舔她的脚》、《我被变身成女生了》、《没有性别的世界》、《女神攻略系统》、《我的奴隶生活》、






